Polos: Multimodal Metric Learning
from Human Feedback for Image Captioning

Fig 1. Our supervised metric Polos computes evaluation scores from multimodal inputs by integrating human feedback within the novel framework $\mathrm{M^2LHF}$. Polos is capable of modeling intricate relationships within the vector space of text-image pairs as well as text-text pairs, thereby effectively evaluating the depicted samples.
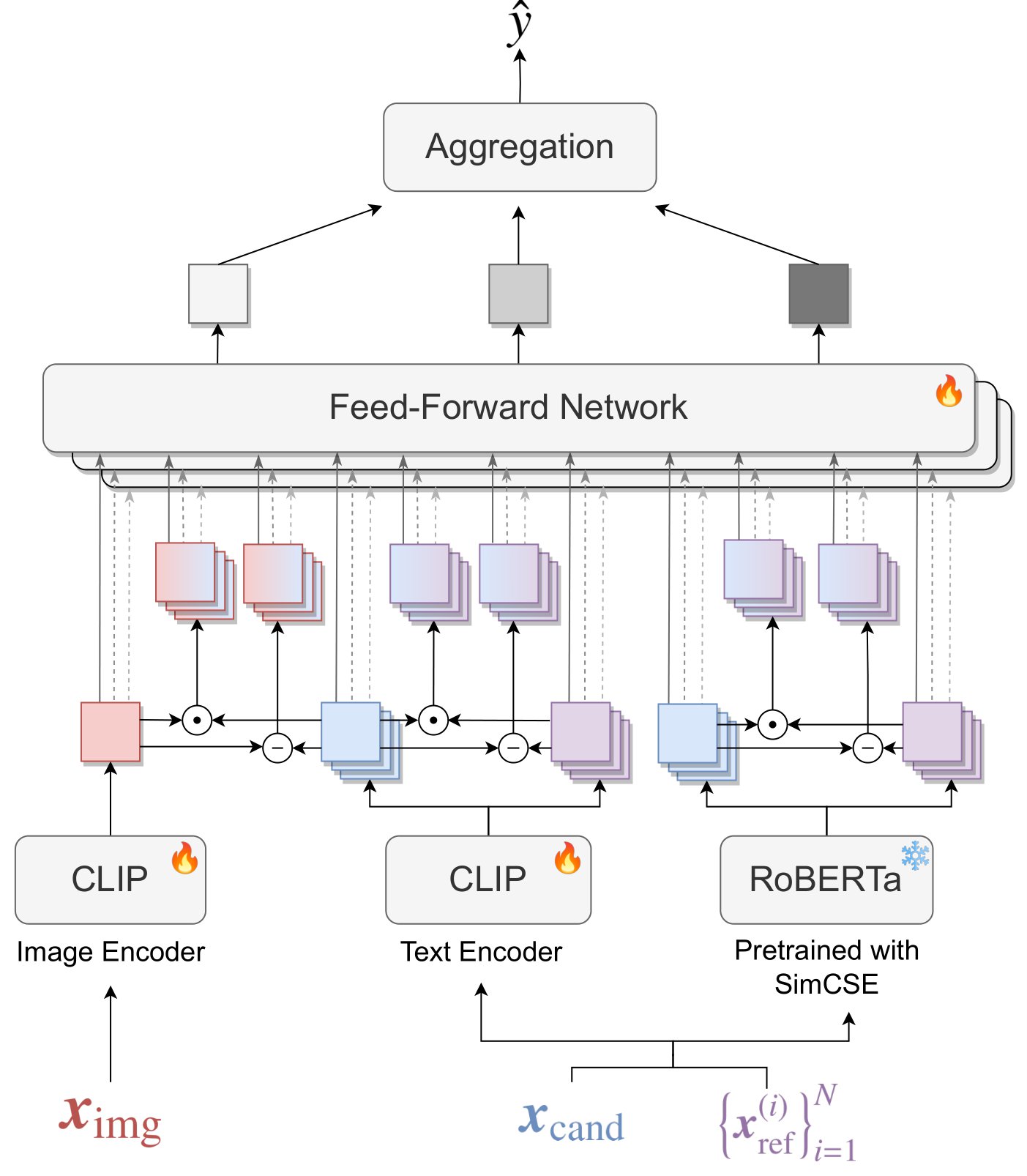
Fig 2. Overview of the proposed metric. In alignment with the principles of $\mathrm{M^2LHF}$, Polos computes the evaluation $\hat{y}$ based on multimodal inputs and regresses the human evaluation. The proposed metric extracts effective features for caption evaluation using the difference and Hadamard product of features derived from both CLIP and RoBERTa.
Table 1. Correlation coefficients between various metrics and human judgments. The symbol `--' indicates non-executable code or unavailable data. Bold font indicates the highest recorded value and underlining indicates the second-highest value..
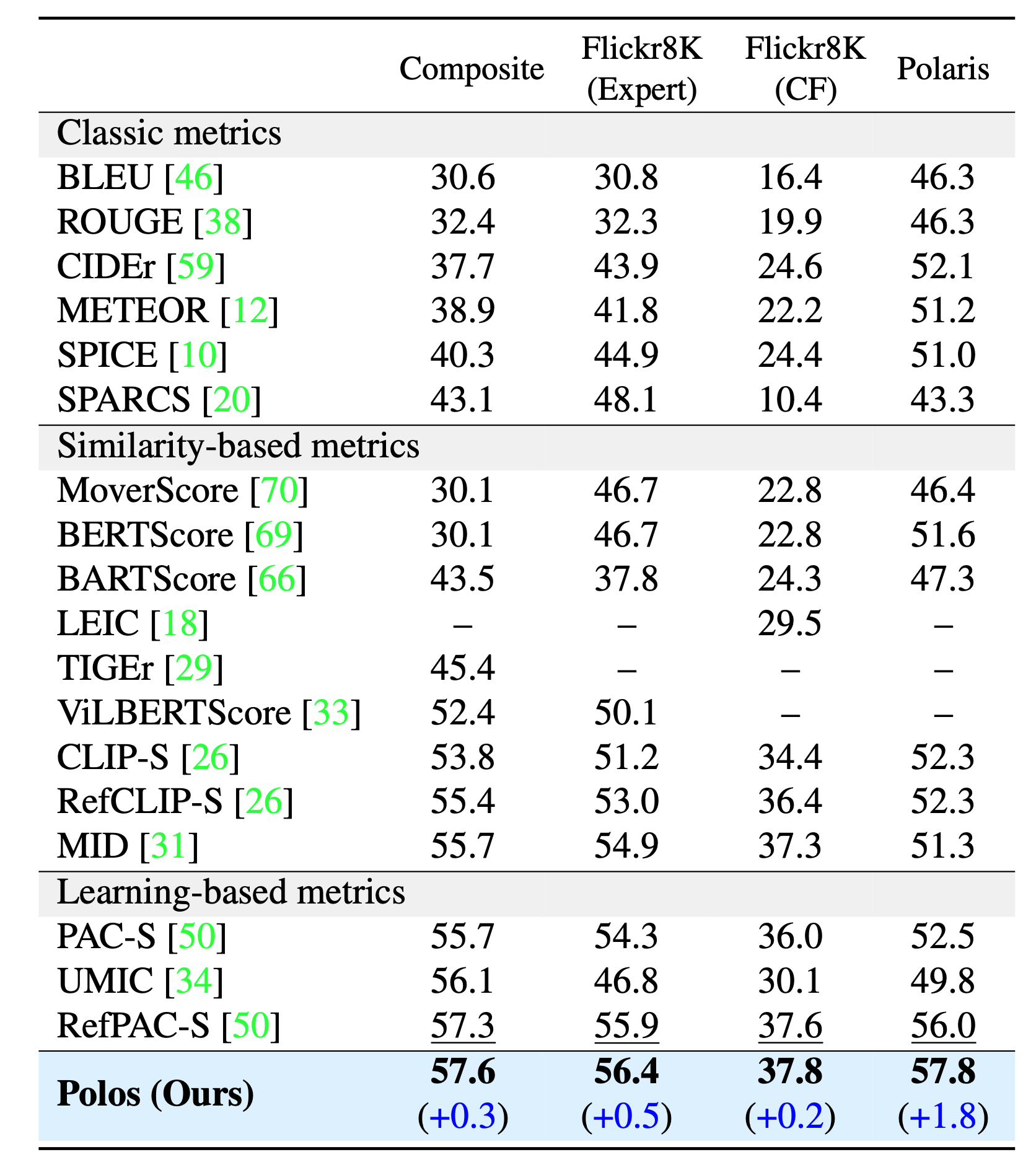
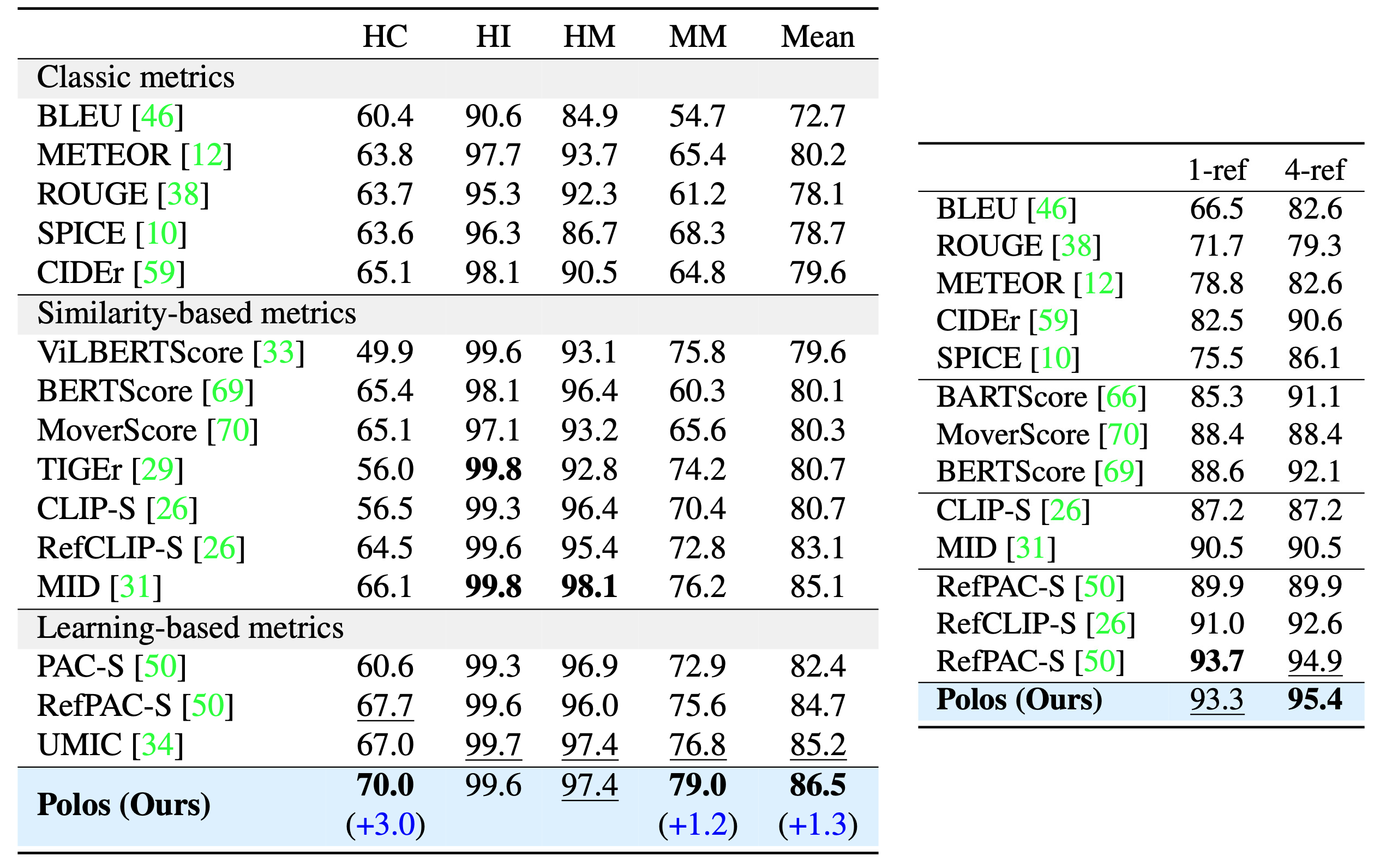
Table 2. Pascal50-S accuracy results (five references) and
FOIL hallucination pairwise detection accuracy results.
to be appear